While ksql has been great to work with, it's too slow for my current needs. This article introduces sqlbox, which has a different API geared for much higher performance while offering the same (if not slightly better) security. This document is based on sqlbox v0.1.5.
background
ksql was started as a way to allow sqlite3 database access within a file-system constrained application process (typically as enacted with pledge). Since sqlite3 is both in-process and on the file-system, this necessitated a separate process with file-system access. Parent and child would communicate synchronously over sockets.

The library has served this purpose admirably. But as my application needs grew into performance alongside security, I found it difficult for ksql to keep up. Several issues arose, which would be difficult to address without drastic API or backend changes:
- Complexity: has both an in-process and split-process mode, the former being unsafe and adding a layer of complexity to everything. See ksql_alloc versus ksql_alloc_child.
- Integrity: lets the application optionally handle database failure, which makes audits of database integrity (database process should close database in a safe state) difficult. This is compounded in the non-split-process mode.
- Performance: sqlite3-modelled API functions are synchronous in that the application requests then receives a response from the database process, so each each operation requires a round-trip.
The performance issues may be visualised by the penalty of creating, opening, operating upon, then closing an in-memory database. (These graphs also show that the process of allocating the database is quite expensive!)
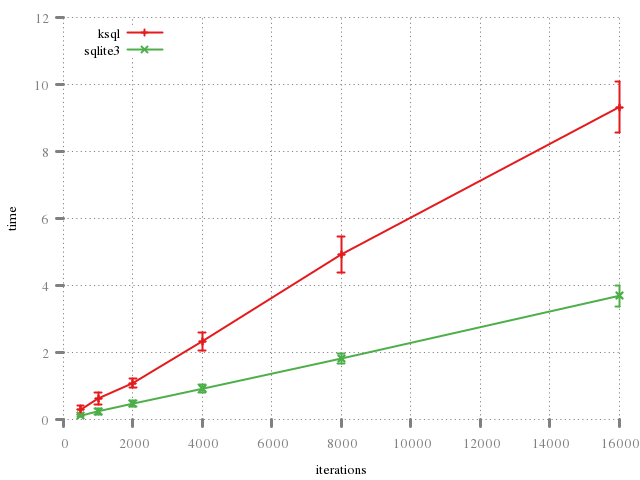
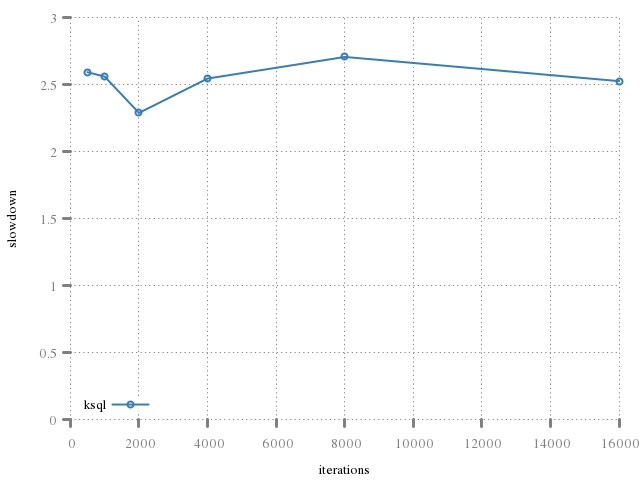
The real cost may be seen in preparing and executing statements, with each step (har, har) along the way being communicated synchronously over a socket communication.
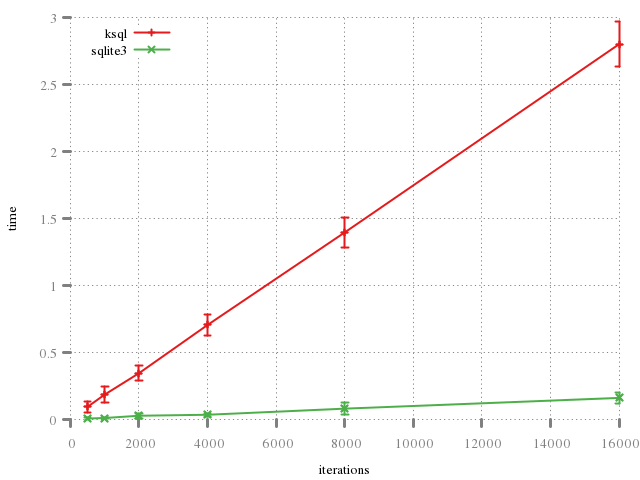
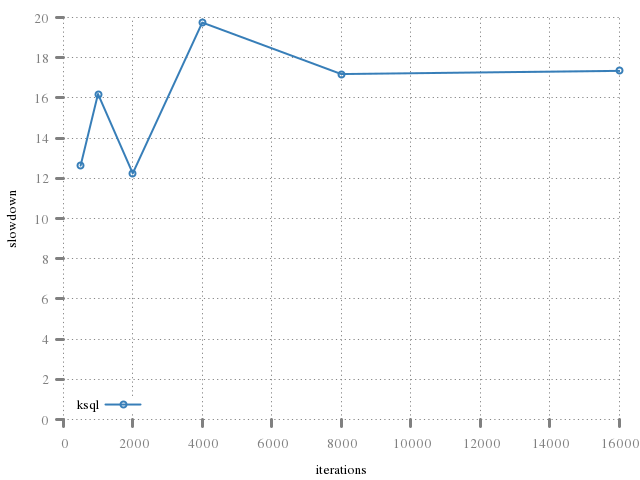
There are similar penalties in acquiring resulting rows, but that I'll discuss later.
To fix some of the issues would require completely overhauling the implementation, such as split-process mode. Others, like performance, would require a significant API change. Since ksql has shown itself to be a very stable piece of software, it makes more sense to simply start again with a new API in a new library, inheriting if not code, then at least backend processes from the origin.
design considerations
In writing sqlbox, I focussed on several points:
- Wait-free operation: by combining close-on-fail with implicit addressing (addressing, for example, the last open statement instead of needing to open the statement and wait for a prior identifier), most operations are wait-free.
- Caching results: have the database process optionally transfer a cache of result rows instead of just a single one, filling the cache between requests. This reduces the number of inter-process communication.
- API compacting: instead of needing to invoke communication for each (for example) bind or resutl operation, reconstitute the API to have these occur all at once. This prevents significant superfluous communication.
Wait-free operation stipulates that the exchange of data between the application and database process, where the former waits for a response from the latter, is limited to only necessary steps. This allows both processes to perform work in between requests, greatly increasing performance.

Caching responses linearly increases performances by having the database process pre-step as many results as possible while waiting. After returning a cached payload, the application simply steps through result rows in memory and need not contact the database application.

For optimum performance, the database process collects results
API redesign compresses the binding operation into statement preparation or execution. This means that instead of invoking one round-trip operation per column, there's only one per statement.

implementation
Like ksql, sqlbox uses native operating system security features to constrain the database process. The application is responsible for doing so itself. On OpenBSD, the platform of choice, this is enacted by pledge. There are options for similar security levels on FreeBSD using Capsicum and overriding how sqlite3 opens files, but this is not currently on the roadmap.
Unlike ksql, sqlbox has a robust set of regression tests to verify that the behaviour stipulated in its manpages is consistent with the implementation. To date, there are over 150 tests. This framework ensures that changes to the implementation do not affect expected behaviour. It also ensures that border conditions are properly handled.
% make regress test-alloc-bad-defrole... ok test-alloc-bad-filt-stmt... ok test-alloc-bad-role... ok test-alloc-bad-src... ok [...] % make valgrind # "regress" but under valgrind
In the code itself, another significant difference is that (with very few exceptions) requests and
responses use fixed-sized minimum packet sizes for communication.
At the moment, this is fixed at 1024 B.
This means that both processes read at least 1K for each communication.
Why?
It allows up to 1K of request data (parameters, response rows, etc.) to be written into each packet with
a single read() instead of requiring one for size, one for data.
Transmissions of greater than 1K read only the remainder.
The choice of 1K is simply to be less than the default socket buffer size.
(It can be tuned at compile time.)
results
Even at this early stage of development, the results are quite impressive. The following chart the overhead of ksql versus sqlbox over the native sqlite3.
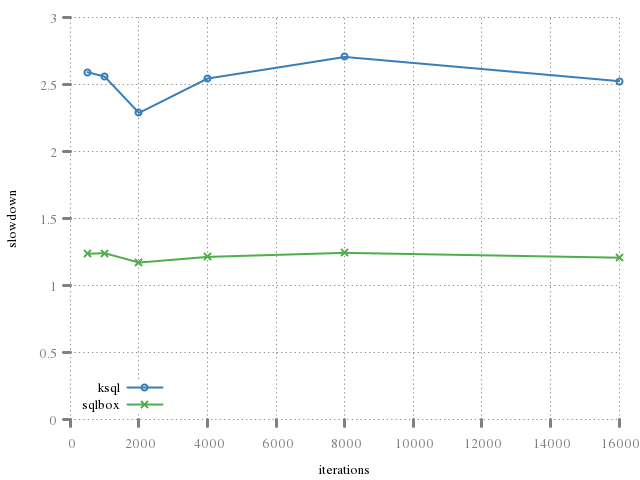
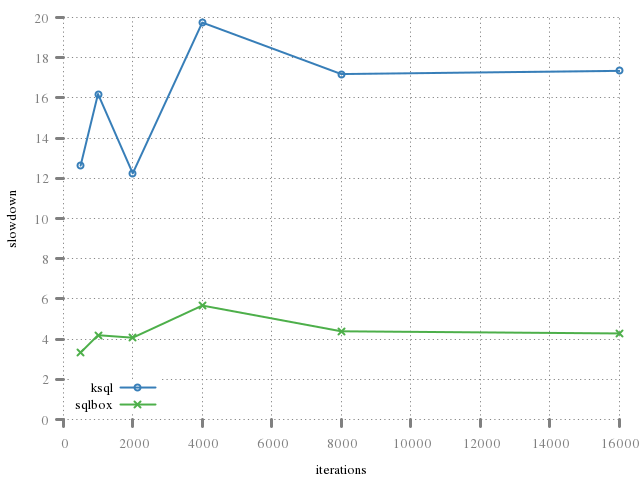
The benefit of the first graph (full-cycle
operation) is not so clear considering that the
underlying expense of creating the database outweighs the communication costs.
The second graph (prepare-bind-step
cycle) is more visible due to the API reflow and wait-free
operation.
The following shows the benefit of caching step statements. The first graph does not cache; the second does. Both use the same code for generating the ksql case. We see, in the first, simply the cost of two synchronous operations transferring bytes. sqlbox is approximately twice as fast because it this in one step.
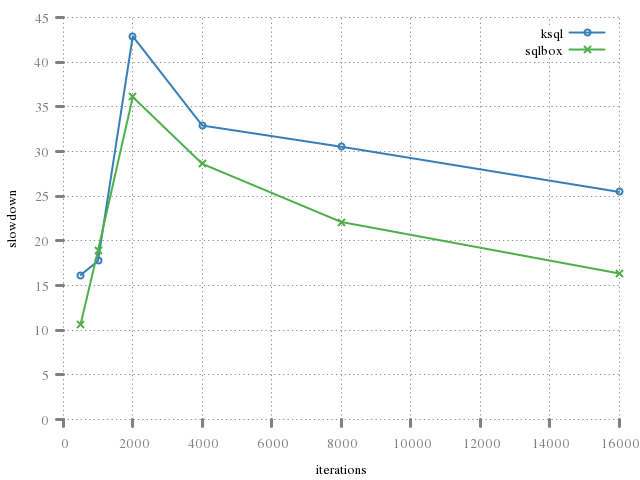
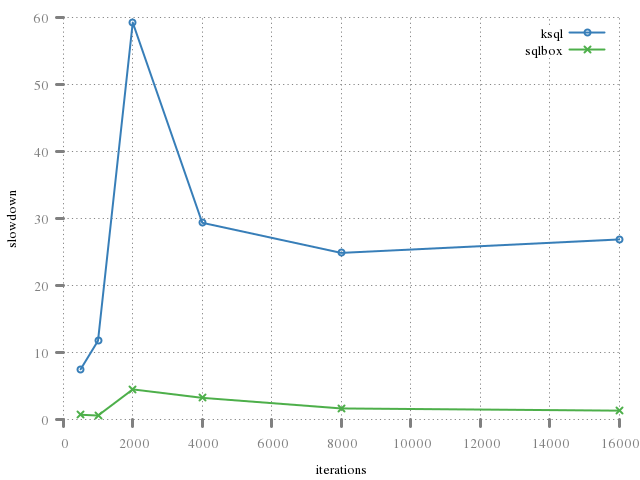
It's clear that stuffing result rows has a noticable benefit in terms of performance.
future work
With a cleaner API and back-end, it's much easier to add further improvements. First, the implementation should compute and exchange the minimum buffer size at startup. This is also necessary for actual socket communication where the buffer sizes will not be symmetric.
Second, the multi-step result caching can be considerably improved. For now it just uses a fixed-sized buffer for gathering results (10K, specifically). This should be determined at run-time.